Création d'un modèle IA classifieur de sentiment binaire spécialisé dans les critiques de jeu vidéo
Deep Learning · NLP · TensorFlow · KerasNLP · FastAPI · Docker
Le projet
Comment j'ai fine-tuné BERT sur 230 000 avis Steam pour battre les modèles génériques.

L'objectif de ce projet est de spécialiser un modèle de deep learning pour classifier automatiquement le sentiment des commentaires de joueurs (positif ou négatif). L'analyse de sentiment (sentiment analysis) est un domaine mature du traitement automatique du langage naturel (NLP). Les techniques modernes reposent principalement sur des modèles pré-entraînés, capables de comprendre le contexte et les nuances du langage. À terme, ce modèle sera intégré dans un service capable d'analyser des centaines d'avis provenant de plusieurs sites spécialisés ou des commentaires sous une vidéo YouTube.
Restituer des tendances de popularité en temps réel
Pour les joueurs : réaliser des achats éclairés, basés sur des avis textuels authentiques, en complément des notes de la critique professionnelle (Metacritic). Pour les professionnels du secteur : suivre les tendances lors de moments clés, sortie d'un trailer, phase de bêta test, déploiement d'une mise à jour majeure.
Le problème : pourquoi les modèles génériques ne suffisent pas
Si vous demandez à un analyseur de sentiment générique ce qu'il pense de la phrase "this game is cancer", il vous répondra probablement... négatif. Et il aurait tort, dans la communauté gaming, cette expression signifie exactement le contraire : que le jeu est tellement addictif qu'il détruit votre vie sociale.
C'est le problème de fond que ce projet cherche à résoudre. La plupart des modèles de sentiment disponibles ont été entraînés sur des critiques de films, des tweets ou des avis Amazon. Ils ignorent le jargon vidéoludique : "pay-to-win garbage", "absolute banger", "the grind is real", "devs actually listen to community". Ce vocabulaire hyper-spécifique brouille le signal pour tout modèle non spécialisé.
L'objectif du projet : fine-tuner BERT sur des avis Steam authentiques pour construire un classifieur de sentiment binaire (positif / négatif) spécialisé dans le domaine du jeu vidéo, et le déployer sous forme d'API REST.
Le dataset : 100 millions d'avis, 40 Go, un vrai défi
Le point de départ est le dataset Kaggle Steam Reviews : environ 100 millions d'avis annotés avec un sentiment en plusieurs langues, soit 40 Go bruts.
Le dataset permet de réaliser un apprentissage supervisé avec pour chaque commentaire le sentiment disponible laissé par le joueur.
Attention, travailler avec cette masse de données demande dès le départ des choix méthodologiques clairs.
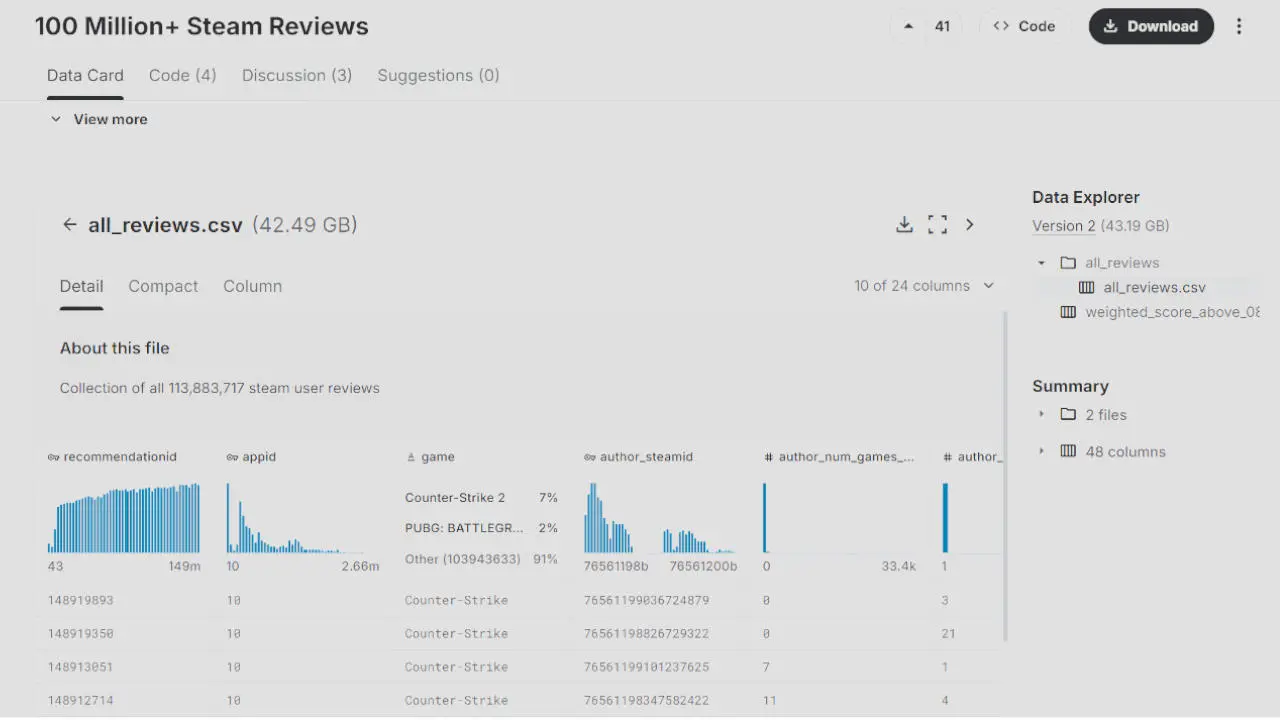
Filtrage de qualité : ne garder que les avis légitimes
Steam dispose d'un système interne appelé weighted_vote_score — un score de crédibilité calculé par Valve pour chaque avis. Ce n'est pas un indicateur de sentiment : c'est une mesure de fiabilité. Les avis générés par des bots ou des campagnes coordonnées tendent à avoir peu de votes, peu d'activité réelle, et donc un score faible.
En croisant ce score avec d'autres métadonnées — temps de jeu (author_playtime_forever), achat vérifié (steam_purchase), absence de clé offerte (received_for_free) — il est possible de filtrer les faux avis de manière efficace, sans avoir besoin d'un modèle dédié.
Pipeline de nettoyage
Chaque avis passe par un pipeline de prétraitement :
- Suppression des balises HTML et BBCode (fréquents dans les avis Steam)
- Détection et suppression des "ASCII art" (certains avis ne contiennent aucun mot)
- Filtre de longueur : entre 10 et 400 mots (pour coller à la fenêtre de 512 tokens de BERT)
- Équilibrage des classes : 50 % positifs / 50 % négatifs par undersampling
Résultats
Après ce travail de filtrage, deux datasets propres sont constitués avec nos deux langues cibles attendues par les personnes du métier :
- Anglais : ~229 000 avis
- Français : ~60 000 avis
Ce volume est à la fois suffisant pour un fine-tuning solide et gérable en termes de temps d'entraînement sur GPU grand public pour de l'expérimentation rapide.
L'architecture : pourquoi BERT et pas autre chose ?
BERT (Bidirectional Encoder Representations from Transformers) est un modèle de langage pré-entraîné sur Wikipedia et des corpus massifs. Sa particularité : il analyse le contexte dans les deux sens (gauche → droite ET droite → gauche), ce qui lui permet de comprendre la nuance et l'ironie bien mieux qu'un modèle unidirectionnel.
Le projet réalisé en Python s'appuie sur KerasNLP (la bibliothèque NLP officielle de Keras 3 / TensorFlow), qui fournit des presets BERT directement utilisables. Trois variantes peuvent être testées sur une machine locale (prévoir néanmoins une carte graphique avec 12 Go de VRAM) :
| Modèle | Preset KerasNLP | Paramètres | Avantage |
|---|---|---|---|
| BERT Small | bert_small_en_uncased | ~28M | Léger, rapide |
| BERT Base | bert_base_en_uncased | ~110M | Bon équilibre |
| DistilBERT Base | distil_bert_base_en_uncased | ~66M | Meilleur rapport perf/vitesse |
Pour adapter BERT à notre cas de classification, on ajoute au-dessus de l'encodeur une tête de classification simple : une couche dense avec activation sigmoid pour produire une probabilité entre 0 (négatif) et 1 (positif).
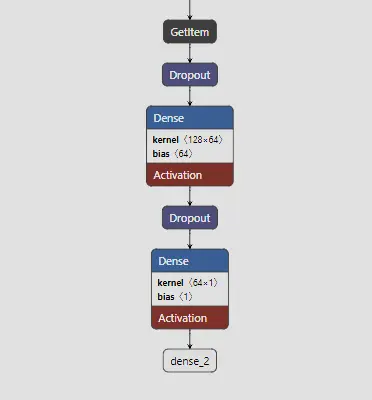
La phase d'expérimentation : Feature Extraction vs Fine-Tuning
Vaut-il mieux geler le modèle IA BERT ou le laisser s'adapter à nos données du domaine ?
Avant de lancer les phases d'optimisation lourdes, on va voir que le modèle BERT n'est pas spécialisé dans le jargon jeux vidéo.
Deux approches sont comparées sur un sous-ensemble de 20 000 avis, avec le preset bert_tiny_en_uncased et un split 80/10/10 (train / validation / test).
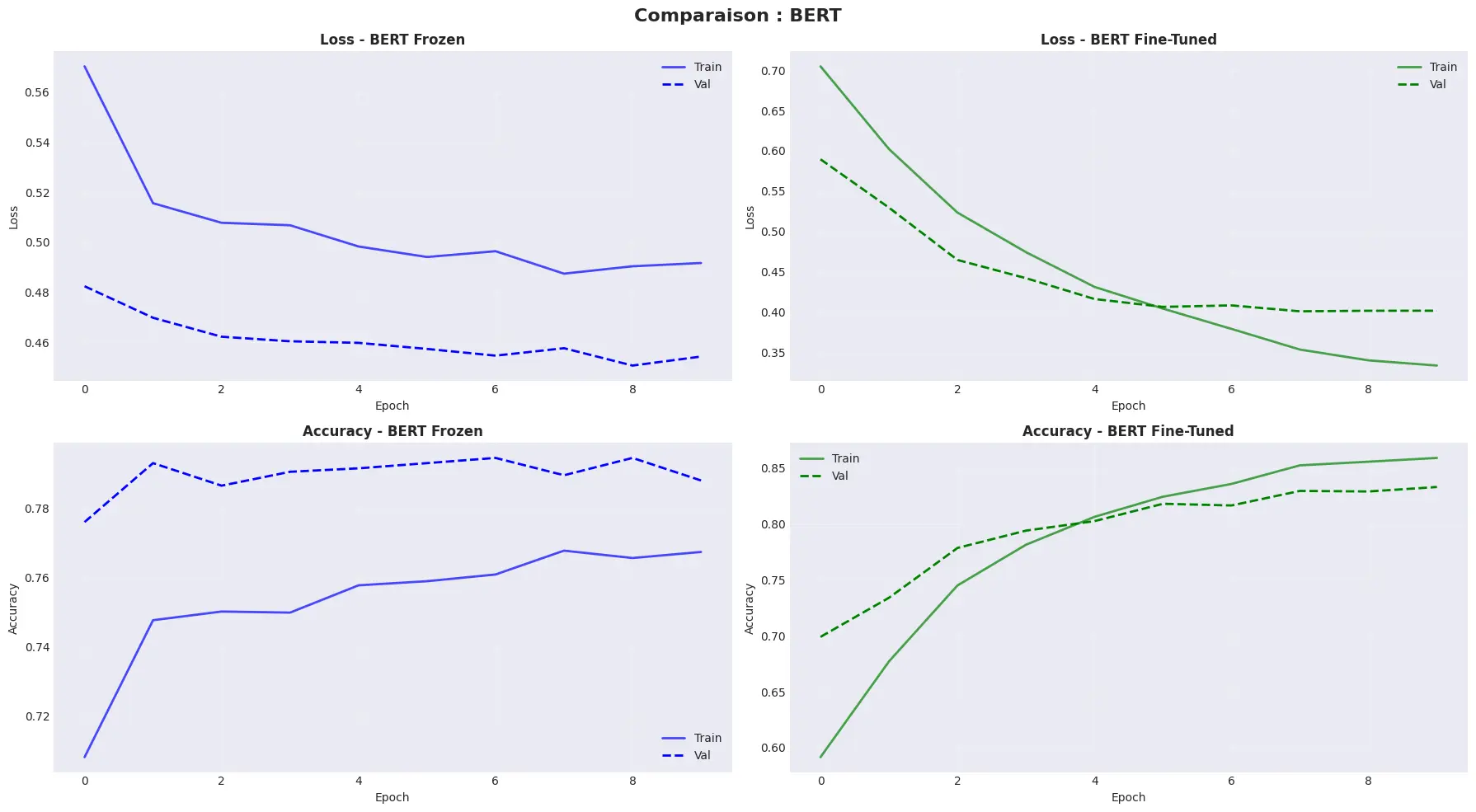
Approche 1 — Feature Extraction (BERT gelé)
Les poids de BERT sont figés (trainable=False) : le modèle se contente d'extraire des représentations fixes, qui sont ensuite transmises à deux couches denses légères. Seules ces couches de sortie s'entraînent, avec un learning rate élevé (1e-3) puisque BERT ne bouge pas. L'avantage : l'entraînement est rapide et stable et BERT est maintenant capable de classifier un sentiment. L'inconvénient : le modèle ne peut pas adapter ses représentations au vocabulaire gaming.
Approche 2 — Fine-Tuning complet
Cette fois, tous les poids de BERT sont déverrouillés (trainable=True). Le modèle réapprend à la fois la tête de classification et les représentations internes de BERT. Un learning rate très faible (2e-5) est utilisé — valeur standard pour le fine-tuning BERT — pour éviter de "détruire" la connaissance pré-entraînée par des mises à jour trop agressives. Des callbacks EarlyStopping et ReduceLROnPlateau encadrent l'entraînement pour prévenir l'overfitting.
Résultats
Le verdict est sans appel : le fine-tuning complet dépasse clairement la feature extraction sur ce dataset. BERT gelé produit des représentations génériques qui ne capturent pas les subtilités du jargon Steam du domaine du jeu vidéo. Le fine-tuning, lui, réoriente les couches d'attention vers le vocabulaire spécifique des joueurs. C'est cette approche qui est retenue pour toutes les phases suivantes.
À ce stade, nous avons déjà un premier modèle spécialisé pour le domaine, mais avec des performances qui sont à améliorer.
Amélioration des performances et stratégie d'entraînement progressive en 4 phases
Cette phase de recherche des meilleures paramètres et performances est la plus coûteuse en temps de calcul. Plutôt que de lancer un seul entraînement lourd au hasard et d'espérer un bon résultat, le projet adopte une stratégie progressive inspirée des bonnes pratiques MLOps.
Phase 1 — Recherche d'hyperparamètres (modèle small, dataset réduit)
Sur 50 000 avis et avec BERT Small, une grille d'expériences teste :
- 3 valeurs de learning rate de départ
- 3 architectures de couche de sortie différentes
- 3 stratégies de callbacks (early stopping, learning rate scheduling)
Soit des dizaines de combinaisons entraînées séquentiellement via un script Python. Chaque entraînement s'exécute en quelques minutes. Les résultats sont exportés dans un fichier CSV pour analyse.
Résultat phase 1 : ~0.88 d'accuracy
Phase 2 — Validation sur le dataset complet
Les 6 meilleures combinaisons de la phase 1 sont reprises et réentraînées sur les 229 000 avis anglais complets, toujours avec BERT Small.
Résultat phase 2 : ~0.90 d'accuracy
Phase 3 — Montée en puissance (BERT Base + DistilBERT)
Les meilleurs hyperparamètres validés en phase 2 sont appliqués aux modèles plus grands. BERT Base et DistilBERT Base sont entraînés sur le dataset complet.
Résultat phase 3 : ~0.92 (BERT Base)
Phase 3.1 — Expérimentation sur la longueur de séquence
Une dernière série de tests évalue l'impact de la longueur de séquence (128, 256, 512 tokens) sur DistilBERT. Les avis Steam dépassent souvent les 128 tokens, et il s'agit de voir si prendre en compte plus de contexte améliore réellement les prédictions.
Résultat phase 3.2 : ~0.93 avec DistilBERT (séquence 256)
Progression globale
| Phase | Modèle | Dataset | Accuracy |
|---|---|---|---|
| Baseline | BERT Small | 20 000 avis | 0.82 |
| Phase 1 | BERT Small | 50 000 avis | 0.88 |
| Phase 2 | BERT Small | 229 000 avis | 0.90 |
| Phase 3 | BERT Base (seq=128) | 229 000 avis | 0.92 |
| Phase 3.1 | DistilBERT (seq=128) | 229 000 avis | 0.91 |
| Phase 3.2 | DistilBERT (seq=256) | 229 000 avis | 0.93 |
Chaque phase apporte un gain mesurable, ce qui valide l'intérêt de la démarche progressive. Le résultat final est aussi une bonne surprise sur le plan pratique : DistilBERT, avec une séquence de 256 tokens, surpasse BERT Base tout en embarquant un tiers de paramètres en moins. Un modèle plus léger, plus rapide à l'inférence, et plus précis : exactement ce qu'on recherche pour analyser des milliers d'avis en production.
Où s'arrêter dans la quête des meilleures performances ?
93 % d'accuracy, c'est un bon résultat mais il serait techniquement possible d'aller plus loin. Des modèles comme RoBERTa (l'optimisation de BERT par Facebook), DeBERTa v3 ou les variantes Large des presets KerasNLP embarquent davantage de paramètres et obtiennent régulièrement de meilleures performances sur les benchmarks NLP.
Le problème, c'est que cette course aux paramètres a un coût réel en production. Un modèle deux fois plus grand, c'est un temps d'inférence deux fois plus long et une facture GPU deux fois plus élevée. Dans le cas de ce projet, un modèle à 91 % qui répond en 50 ms sera souvent plus utile qu'un modèle à 94 % qui répond en 300 ms.
DistilBERT Base avec une séquence de 256 tokens représente ici un bon point d'équilibre : il concentre l'essentiel de la capacité de compréhension de BERT Base, avec un tiers de paramètres en moins. C'est ce compromis performance/vitesse qui guide le choix du modèle de production, plutôt qu'une optimisation aveugle du score de validation.
Comparaison avec les approches existantes
Pour valider la valeur ajoutée de ce fine-tuning spécialisé, le modèle est comparé à deux baselines classiques.
VADER — l'approche lexicale
VADER (Valence Aware Dictionary and sEntiment Reasoner) est un outil de sentiment basé sur un dictionnaire de mots positifs et négatifs. Il ne comprend pas le contexte, ne capte pas les négations complexes, et ignore totalement le jargon gaming.
Sur un avis mitigé comme "It's decent, nothing groundbreaking", VADER retourne un score composé de exactement 0.0 — parfaitement neutre, donc inutilisable.
Accuracy VADER : ~70 %
DistilBERT générique (SST-2, avis de films)
Un modèle DistilBERT pré-fine-tuné sur le dataset SST-2 (critiques de films) obtient de meilleures performances, mais reste limité par son domaine d'entraînement. Le vocabulaire cinéphile ne recouvre pas le vocabulaire gamer.
Accuracy DistilBERT générique : ~85 % (estimé)
Notre modèle — BERT fine-tuné sur Steam
Accuracy : 91–93 %
Soit un gain de +6 % sur les modèles génériques et +21 % sur la baseline lexicale. Ce delta n'est pas anecdotique : sur 1 000 avis, c'est 60 à 210 prédictions supplémentaires correctes.
Un exemple concret illustre bien la différence. Sur la phrase "It's decent, nothing groundbreaking" :
- VADER : positif, confiance 0 %
- BERT Small : négatif, confiance 52 %
- BERT Base : positif, confiance 73 %
BERT Base a correctement interprété que "decent" implique une nuance légèrement positive, là où le mot "nothing" a trompé le modèle plus petit.
| Avis | Sentiment prédit | Confiance |
|---|---|---|
| "Best purchase I've made this year" | POSITIF | 99.99 % |
| "Full of bugs, crashes constantly" | NÉGATIF | 99.93 % |
| "It's decent, nothing groundbreaking" | POSITIF | 73.24 % |
Le déploiement : FastAPI + Docker + AWS
Le modèle final (BERT Base, format .keras) est exposé via une API REST construite avec FastAPI et conteneurisée avec Docker.
Un endpoint AWS SageMaker a été créé : une solution entièrement gérée avec un overhead opérationnel minimal et ne nécessitant pas de personnalisation avancée.
L'endpoint a été configuré avec Amazon SageMaker Serverless Inference à la demande (modèle pay-per-use — Serverless Inference est une option économique si vous avez un trafic irrégulier ou imprévisible).
Notes sur les reviews françaises
Pour les reviews françaises, le travail a été réalisé sur les modèles multilingues en utilisant des fournisseurs cloud AWS SageMaker et Google Colab.
- CamemBERT : Version française de RoBERTa, spécialisée pour le français (Hugging Face Transformers)
Ce que j'ai appris
Ce projet m'a permis de travailler de bout en bout sur une problématique NLP réelle, de la donnée brute jusqu'au déploiement :
Sur les données : La qualité des données d'entraînement est déterminante. Travailler avec 40 Go de données brutes oblige à construire des pipelines robustes, à comprendre les biais du dataset, et à faire des choix méthodologiques explicites plutôt que de tout garder "par sécurité".
Sur l'entraînement : L'approche par phases est bien plus efficace qu'un seul gros run. Elle permet de valider les hypothèses progressivement, d'économiser du temps GPU, et de garder une trace claire de chaque décision.
Sur le déploiement : Docker simplifie énormément la reproductibilité. L'endpoint serverless sur AWS SageMaker et ECS permet également une mise en production simple incluant tous les outils de monitoring et de contrôle.
Le projet complet est disponible sur GitHub, incluant tous les notebooks d'exploration, les scripts d'entraînement, et le code minimal de l'API Docker.
Cet article fait partie d'une série sur mes expériences professionnelles dans le développement de solutions innovantes. Pour découvrir d'autres projets, consultez mon portfolio..