Creating a Binary Sentiment Classifier AI Specialized in Video Games Reviews
Deep Learning · NLP · TensorFlow · KerasNLP · FastAPI · Docker
The Project
How I fine-tuned BERT on 230,000 Steam reviews to outperform generic models.

The goal of this project is to specialize a deep learning model to automatically classify the sentiment of player reviews (positive or negative). Sentiment analysis is a mature field in natural language processing (NLP). Modern techniques rely primarily on pre-trained models capable of understanding context and language nuances. Eventually, this model will be integrated into a service capable of analyzing hundreds of reviews from multiple specialized websites or comments under a YouTube video.
Delivering Real-Time Popularity Trends
For players: making informed purchases based on authentic text reviews, complementing professional critic scores (Metacritic). For industry professionals: tracking trends at key moments — trailer releases, beta testing phases, major update deployments.
The Problem: Why Generic Models Fall Short
If you ask a generic sentiment analyzer what it thinks of "this game is cancer", it will probably answer... negative. And it would be wrong — in the gaming community, this expression means exactly the opposite: that the game is so addictive it destroys your social life.
This is the core problem this project aims to solve. Most available sentiment models have been trained on movie reviews, tweets, or Amazon feedback. They ignore gaming jargon: "pay-to-win garbage", "absolute banger", "the grind is real", "devs actually listen to community". This hyper-specific vocabulary blurs the signal for any non-specialized model.
The project objective: fine-tune BERT on authentic Steam reviews to build a binary sentiment classifier (positive / negative) specialized in the video game domain, and deploy it as a REST API.
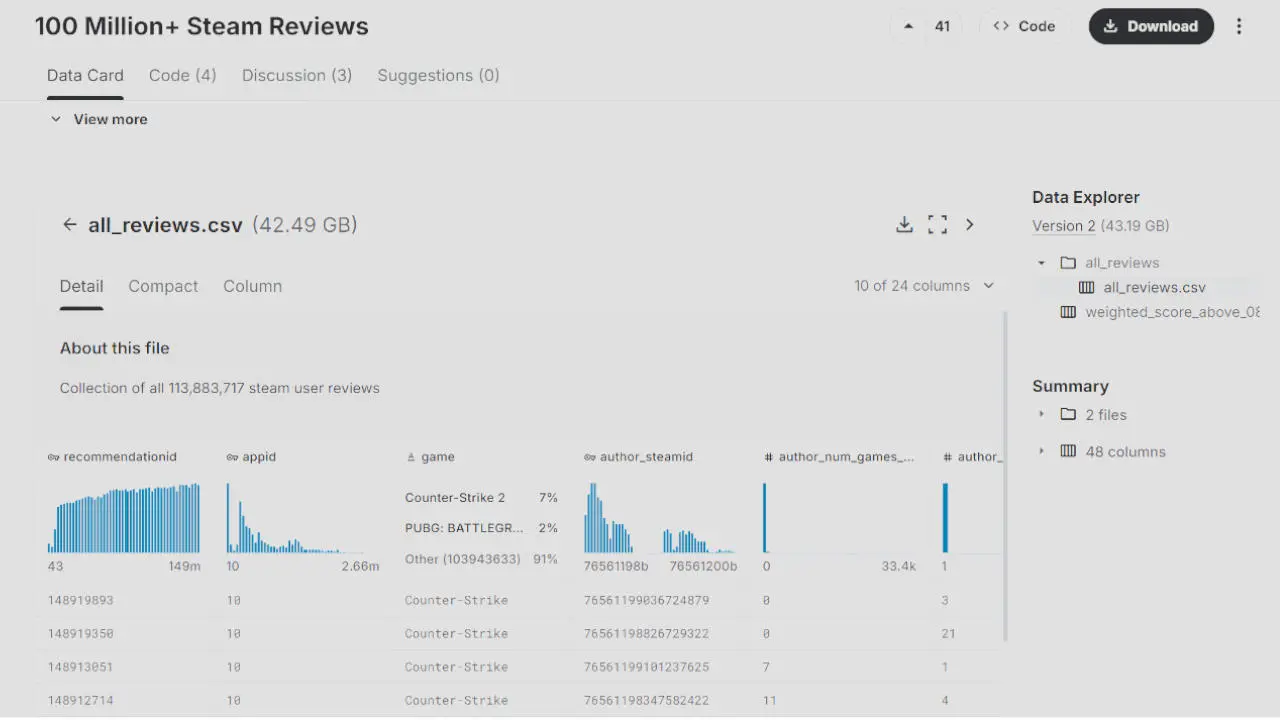
The Dataset: 100 Million Reviews, 40 GB, a Real Challenge
The starting point is the Kaggle Steam Reviews dataset: approximately 100 million reviews annotated with sentiment in multiple languages, totaling 40 GB of raw data.
The dataset enables supervised learning with the player-provided sentiment available for each review.
Working with this volume of data requires clear methodological decisions from the start.
Quality Filtering: Keeping Only Legitimate Reviews
Steam has an internal system called weighted_vote_score — a credibility score calculated by Valve for each review. This is not a sentiment indicator: it is a reliability measure. Reviews generated by bots or coordinated campaigns tend to have few votes, little real activity, and therefore a low score.
By cross-referencing this score with other metadata — playtime (author_playtime_forever), verified purchase (steam_purchase), no gifted key (received_for_free) — fake reviews can be filtered effectively, without needing a dedicated model.
Cleaning Pipeline
Each review passes through a preprocessing pipeline:
- Removal of HTML and BBCode tags (common in Steam reviews)
- Detection and removal of "ASCII art" (some reviews contain no actual words)
- Length filter: between 10 and 400 words (to fit within BERT's 512-token window)
- Class balancing: 50% positive / 50% negative via undersampling
Results
After this filtering work, two clean datasets are produced for the two target languages expected by industry professionals:
- English: ~229,000 reviews
- French: ~60,000 reviews
This volume is both sufficient for solid fine-tuning and manageable in terms of training time on consumer-grade GPU hardware for rapid experimentation.
The Architecture: Why BERT and Not Something Else?
BERT (Bidirectional Encoder Representations from Transformers) is a language model pre-trained on Wikipedia and massive corpora. Its key feature: it analyzes context in both directions (left → right AND right → left), enabling it to understand nuance and irony far better than a unidirectional model.
The project, written in Python, relies on KerasNLP (the official NLP library of Keras 3 / TensorFlow), which provides ready-to-use BERT presets. Three variants can be tested on a local machine (though a GPU with 12 GB VRAM is recommended):
| Model | KerasNLP Preset | Parameters | Advantage |
|---|---|---|---|
| BERT Small | bert_small_en_uncased | ~28M | Lightweight, fast |
| BERT Base | bert_base_en_uncased | ~110M | Good balance |
| DistilBERT Base | distil_bert_base_en_uncased | ~66M | Best performance/speed ratio |
To adapt BERT to our classification task, a simple classification head is added on top of the encoder: a dense layer with sigmoid activation to produce a probability between 0 (negative) and 1 (positive).
The Experimentation Phase: Feature Extraction vs Fine-Tuning
Should We Freeze BERT or Let It Adapt to Domain Data?
Before launching the heavy optimization phases, we verify that the BERT model is not specialized in gaming jargon.
Two approaches are compared on a subset of 20,000 reviews, using the bert_tiny_en_uncased preset and an 80/10/10 split (train / validation / test).
Approach 1 — Feature Extraction (Frozen BERT)
BERT's weights are frozen (trainable=False): the model only extracts fixed representations, which are then fed to two lightweight dense layers. Only these output layers train, with a high learning rate (1e-3) since BERT doesn't move. The advantage: training is fast and stable, and BERT can now classify sentiment. The downside: the model cannot adapt its representations to gaming vocabulary.
Approach 2 — Full Fine-Tuning
This time, all BERT weights are unlocked (trainable=True). The model relearns both the classification head and BERT's internal representations. A very low learning rate (2e-5) is used — the standard value for BERT fine-tuning — to avoid "destroying" the pre-trained knowledge with overly aggressive updates. EarlyStopping and ReduceLROnPlateau callbacks frame the training to prevent overfitting.
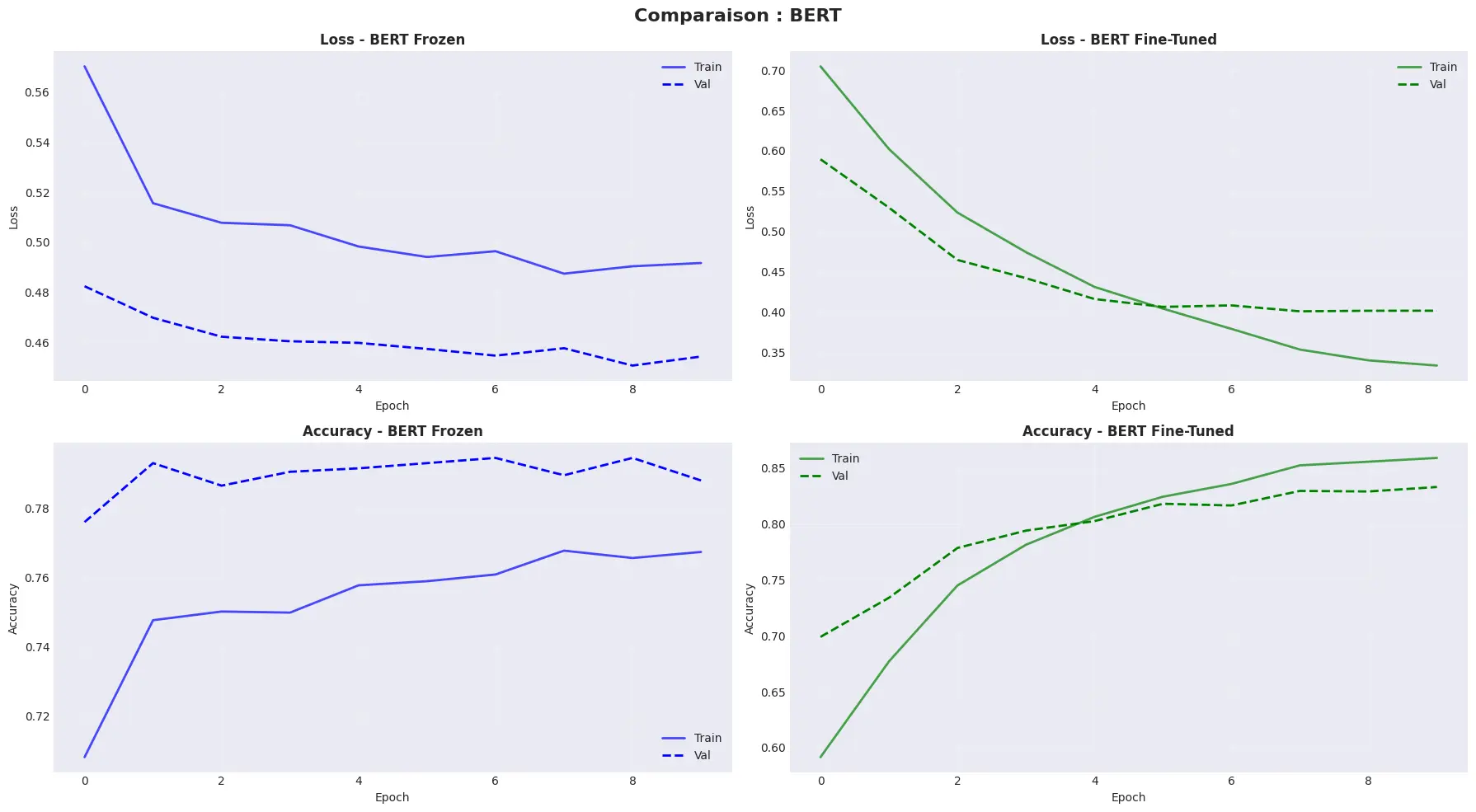
Results
The verdict is clear: full fine-tuning clearly outperforms feature extraction on this dataset. Frozen BERT produces generic representations that fail to capture the subtleties of Steam's gaming jargon. Fine-tuning redirects the attention layers toward the player-specific vocabulary. This approach is retained for all subsequent phases.
At this stage, we already have a first domain-specialized model, but with performance that still needs improvement.
Performance Improvement and 4-Phase Progressive Training Strategy
This phase of searching for optimal parameters and performance is the most computationally expensive. Rather than launching a single heavy training run and hoping for good results, the project adopts a progressive strategy inspired by MLOps best practices.
Phase 1 — Hyperparameter Search (Small Model, Reduced Dataset)
On 50,000 reviews with BERT Small, an experiment grid tests:
- 3 starting learning rate values
- 3 different output layer architectures
- 3 callback strategies (early stopping, learning rate scheduling)
That is dozens of combinations trained sequentially via a Python script. Each training run executes in a few minutes. Results are exported to a CSV file for analysis.
Phase 1 result: ~0.88 accuracy
Phase 2 — Validation on the Full Dataset
The 6 best combinations from Phase 1 are retrained on the full 229,000 English reviews, still with BERT Small.
Phase 2 result: ~0.90 accuracy
Phase 3 — Scaling Up (BERT Base + DistilBERT)
The best hyperparameters validated in Phase 2 are applied to larger models. BERT Base and DistilBERT Base are trained on the full dataset.
Phase 3 result: ~0.92 (BERT Base)
Phase 3.1 — Sequence Length Experimentation
A final series of tests evaluates the impact of sequence length (128, 256, 512 tokens) on DistilBERT. Steam reviews often exceed 128 tokens, and the question is whether accounting for more context actually improves predictions.
Phase 3.2 result: ~0.93 with DistilBERT (sequence 256)
Overall Progression
| Phase | Model | Dataset | Accuracy |
|---|---|---|---|
| Baseline | BERT Small | 20,000 reviews | 0.82 |
| Phase 1 | BERT Small | 50,000 reviews | 0.88 |
| Phase 2 | BERT Small | 229,000 reviews | 0.90 |
| Phase 3 | BERT Base (seq=128) | 229,000 reviews | 0.92 |
| Phase 3.1 | DistilBERT (seq=128) | 229,000 reviews | 0.91 |
| Phase 3.2 | DistilBERT (seq=256) | 229,000 reviews | 0.93 |
Each phase delivers a measurable gain, validating the value of the progressive approach. The final result is also a pleasant practical surprise: DistilBERT with a 256-token sequence outperforms BERT Base while having one-third fewer parameters. A lighter, faster-to-inference, and more accurate model — exactly what we want for analyzing thousands of reviews in production.
Where to Stop in the Quest for Best Performance?
93% accuracy is a solid result, but technically it would be possible to go further. Models like RoBERTa (Facebook's BERT optimization), DeBERTa v3, or the Large variants of KerasNLP presets carry more parameters and regularly achieve better performance on NLP benchmarks.
The problem is that this parameter race has a real cost in production. A model twice as large means inference time twice as long and a GPU bill twice as high. In this project's context, a 91% model that responds in 50ms will often be more useful than a 94% model that responds in 300ms.
DistilBERT Base with a 256-token sequence strikes a good balance here: it concentrates the essential understanding capacity of BERT Base with one-third fewer parameters. It is this performance/speed trade-off that guides the production model choice, rather than blind optimization of the validation score.
Comparison with Existing Approaches
To validate the added value of this specialized fine-tuning, the model is compared against two classic baselines.
VADER — The Lexical Approach
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a sentiment tool based on a dictionary of positive and negative words. It does not understand context, cannot capture complex negations, and completely ignores gaming jargon.
On a mixed review like "It's decent, nothing groundbreaking", VADER returns a compound score of exactly 0.0 — perfectly neutral, hence unusable.
VADER Accuracy: ~70%
Generic DistilBERT (SST-2, Movie Reviews)
A DistilBERT model pre-fine-tuned on the SST-2 dataset (movie reviews) achieves better performance, but remains limited by its training domain. Film vocabulary does not cover gamer vocabulary.
Generic DistilBERT Accuracy: ~85% (estimated)
Our Model — BERT Fine-Tuned on Steam
Accuracy: 91–93%
That is a gain of +6% over generic models and +21% over the lexical baseline. This delta is not trivial: on 1,000 reviews, that is 60 to 210 additional correct predictions.
A concrete example illustrates the difference well. On the phrase "It's decent, nothing groundbreaking":
- VADER: positive, 0% confidence
- BERT Small: negative, 52% confidence
- BERT Base: positive, 73% confidence
BERT Base correctly interpreted that "decent" implies a slightly positive nuance, whereas the word "nothing" fooled the smaller model.
| Review | Predicted Sentiment | Confidence |
|---|---|---|
| "Best purchase I've made this year" | POSITIVE | 99.99% |
| "Full of bugs, crashes constantly" | NEGATIVE | 99.93% |
| "It's decent, nothing groundbreaking" | POSITIVE | 73.24% |
Deployment: FastAPI + Docker + AWS
The final model (BERT Base, .keras format) is exposed via a REST API built with FastAPI and containerized with Docker.
An AWS SageMaker endpoint was created: a fully managed solution with minimal operational overhead that does not require advanced customization.
The endpoint was configured with On-demand Amazon SageMaker Serverless Inference (pay-per-use model — Serverless Inference is a cost-effective option for irregular or unpredictable traffic patterns).
Notes on French Reviews
For French reviews, the work was carried out using multilingual models with AWS SageMaker and Google Colab cloud providers.
- CamemBERT: French version of RoBERTa, specialized for French (Hugging Face Transformers)
What I Learned
This project allowed me to work end-to-end on a real NLP challenge, from raw data to deployment:
On data: Training data quality is decisive. Working with 40 GB of raw data requires building robust pipelines, understanding dataset biases, and making explicit methodological choices rather than keeping everything "just in case."
On training: The phased approach is far more efficient than a single large run. It allows hypotheses to be validated progressively, saves GPU time, and maintains a clear record of each decision.
On deployment: Docker greatly simplifies reproducibility. The serverless endpoint on AWS SageMaker and ECS also enables simple production deployment including all monitoring and control tools.
The complete project is available on GitHub, including all exploration notebooks, training scripts, and the minimal Docker API code.
This article is part of a series on my professional experiences in developing innovative solutions. To discover more projects, visit my portfolio..